
提升单芯片多处理性能之并行编程
在指定的实现技术下,要将单个处理器性能发挥到极致并不容易。更快的时钟,更深的管线和更大的缓存都会导致占用更大的硅片面积和功耗开销,并有可能使得最后10%的性能增益化为乌有。有些时候没有其它选择,只能靠提高时钟速率,升级电源和冷却子系统。但是将处理任务分配到多个处理器的做法可以最大程度提升整体性能极限,处理器设计也会更简单、更高效。
当今的许多嵌入式系统级芯片(SoC)设计已经在使用多个处理器,不过,它们都是以一种特定应用或松散结合的方式实现。直到最近,针对软件友好的多处理SoC设计功能还是受限。如今市场已经有诸如MIPS32 1004K一致处理系统(CPS)这种新的SoC设计组件推出,意味着在单操作系统环境中片上对称多处理(SMP)技术已经成为现实。
虽然并行编程会使软件工程师感到恐惧,因为并不是全部现有代码都是针对并行处理平台编写的,但针对并行软件已经有多种范例,其中一些对于软件设计师是来说已经是很熟悉的了。
数据并行算法
数据并行算法通过划分数据集来使用一个以上的处理器,甚至数量众多的CPU。在教科书中,大的数据集通常是一种很大的输入文件或数组,但在嵌入式系统中,它可能意味着高的I/O和事件服务带宽。在一些SoC架构中,多个输入数据源(如网络接口端口)可以被静态地分配到运行相同驱动程序/路由程序代码的多个处理器上,从而实现自然的数据并行处理。
当对单个数组或输入流应用多处理器技术时,“分而治之”的数据并行算法很常见。这样的算法对于单处理器来说通常不是最优的,但是因为具有更多的计算带宽,因此可以弥补效率的不足。这些算法对并行计算来说是可扩展的,但是将一个正常工作的顺序执行程序转换成一个并行数据算法可能面临价值不高、困难或不可能的局面,具体情况取决于程序依赖特性等因素。为了提高性能,如果绝大部分的应用计算都是用很少量的常规运算循环来实现的话,系统设计师很可能毫不犹豫地采用数据并行算法。
用于PC、工作站、服务器的多内核X86芯片的出现催生了新的库和工具套件,它们可以帮助设计师在数量适中的处理器上更容易地建立和开发并行算法。对于像MIPS这样的嵌入式架构来说许多算法都是开源和可移植的。针对数据并行C/C++以及Fortran的GCC扩展已经成为标准GNU编译器集的一个组成部分。
图1左:复杂模块化多任务处理嵌入式软件系统通常表现出“偶发”的并行特性。在使用时间共享的OS时,每个任务必须运行在独立的处理器上。而在一个时间共享的单处理器上,每个任务将在不同时间片中轮流执行。在一个采用了SMP OS的多处理器上,任务将在多个处理器上并行运行。
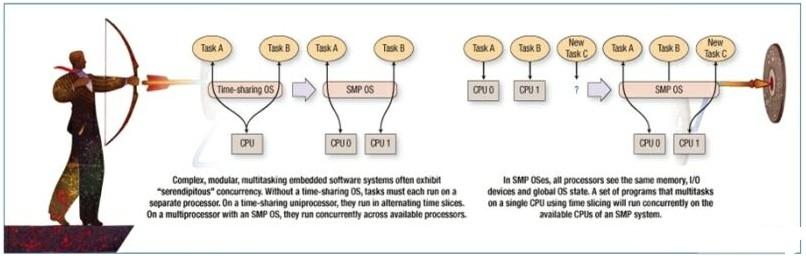
图1右:在SMP OS中,所有处理器都能看到相同的存储器、I/O器件和全局OS状态。在使用时间片的单CPU上执行多任务的一组程序可以在SMP系统的多个CPU上并行运行。
并行控制编程
并行控制编程将根据任务而不是输入进行工作划分。如果将100通道的并行数据算法比作汽车工厂内100个工人各自在组装一辆汽车,那么并行控制程序就可以比作有100个工作岗位的组装线,每个岗位完成百分之一的工作。组装线通常效率更高,但是组装一辆汽车的工作可能只能进行这样的分工。对于可以扩展到多达数千个处理器的科学计算程序而言,这个限制影响很大,但是对于一般的并行SoC架构来说不是问题。
软件工程师经常将程序划分成若干个阶段以便于编码、调试和维护,并减轻指令存储器和缓存的压力。通常,并行控制分解在OS可视任务层面就已经完成。在类似Unix这样的系统中,单指令“cc”顺序地调用C语言预处理器、编译器、汇编器和目标代码连接器。其中几个可以同时运行,每个后续程序使用前一个阶段的输出作为其输入,并使用类似Unix这样的OS内的文件或软件管线。
当分解成独立运行的任务还没有完成的时候,需要某些软件工程使应用阶段对OS和底层硬件可见,并且在任务之间明确地传递数据。但是不需要对部分阶段算法进行重写。粗粒度的任务分解可以通过文件、套接字或管线实现进程通信来完成。对于细粒度控制,许多OS支持Posix线程API、pthreads,包括Linux、微软的Windows和多种实时操作系统。
复杂的模块化多任务嵌入式软件系统通常表现出偶然的并行特性。整个系统任务可能涉及到对应不同输入而具有不同功能的多个任务。当没有时间共享的OS时,每个任务必须运行在一个独立的处理器上。而在一个时间共享的单处理器上,每个任务将在不断轮换的时间片中运行。在一个采用SMP操作系统的多处理器上,每个任务可以在多个可用的处理器上并行运行。
分布式处理
分布式计算,特别是网络客户服务器模式很常见,以至于有时不被认为是“并行”的。客户服务器编程基本上是一种控制流程分解的形式。程序任务并不是独自执行所有的计算,而是将工作请求发送到针对特定目标分配的专用系统任务。客户服务器编程大多数在LAN和WAN中完成,但是SMP SoC遵循相同的范例。未作修改的客户服务器二进制代码可以通过片上或空环回网络接口实现TCP/IP通信,或者利用本地通信协议在存储器中传递数据缓冲器实现更有效的通信。
可以通过单独使用或者组合使用这些技术来充分发挥SMP的处理器能力。有人甚至可能构建一组采用并行数据计算的分布式SMP服务器,每个服务器实现一条控制流管线。
在有可能通过将任务静态地物理分解到处理器上实现并行机制的SoC系统中,将并行任务分配到各个处理器可以由硬件实现。这样做能减少软件开销和物理尺寸,但是缺乏灵活性。
如果一个嵌入式应用可以静态地分解到通过片上互联通信的客户机和服务器,那么整合整个系统所需要的唯一系统软件就是实现一个公共协议的消息传递代码。消息传递协议提供了一个抽象等级,它能帮助采用更多或更少处理器的配置运行最基本的应用代码,但是对于任何一个配置来说,在处理器之间的负载均衡与硬件分割一样是静态的。更灵活的并行系统编程可以由具有共享资源的多处理器系统之上的软件任务分配实现。
在SMP操作系统中,所有的处理器面对的是相同的存储器、I/O器件和全局OS状态,从而使得处理器之间的程序移植简单而高效,负载均衡也非常容易。不需要额外的编程或系统管理,在使用时间片的单个CPU上执行多任务的一组程序可以并行地运行在SMP系统的多个CPU上。像Linux中一样,SMP调度器对程序的处理器资源占用进行切换。
作为多进程运行的Linux应用程序不需要修改就可以利用SMP并行特性,而且通常不需要进行重新编译。SMP Linux环境提供了很多工具,用于调整任务如何共享可用的处理器资源―提高/降低任务的优先级,或者限制任务运行在任意的处理器子集上。适当的内核支持可以实现不同的实时调度机制。
类似于Unix的OS总是能为应用程序提供针对相对任务调度优先级的某种控制,即使在单处理器时间共享系统中。传统的外部命令和系统调用在Linux系统中通过更加精心设计的机制得到了增强,可以控制任务优先级、任务组或特定的系统用户。而且,在多处理器配置中,每一个Linux任务都具有一个参数,这个参数规定了那一组处理器可以调度该任务。默认参数是整个系统处理器组,但是这种CPU关系是可以控制的。
SMP范例要求所有处理器能访问相同地址下的所有存储器。对于低性能的处理器来说,这是通过将所有处理器的取指和加载/保存流放到公共的存储和I/O总线上实现的。然而这种模式随着处理器的增多将很快失去效用,因为总线成为了瓶颈。即使在单处理器系统中,高性能嵌入式内核的指令和数据带宽要求规定缓存必须在主存储器和处理器之间使用。
每个处理器都有独立缓存的系统不再必然是SMP。当一个处理器的缓存保存了存储器中最新位置值的唯一拷贝时,就是不对称的了。必须增加缓存一致性协议才能恢复对称性。
在所有处理器都连接到公共总线的简单系统中,缓存控制器可以通过监测总线来观察哪一个缓存保存了最新的指定存储器位置。在更先进的系统中,处理器是利用到交换结构的点对点连接连接到存储器的,因此缓存一致性需要更复杂的支持。一致性管理单元应该对存储器事务施加全局指令,并产生干涉信号来维护处理器内核之间的缓存一致性。
像Linux这样的SMP OS能够自由地移植任务,动态地均衡处理器负载。在嵌入式SoC中,很大部分的总体计算可以用中断服务完成。好的负载均衡和性能调整需要对发生中断服务的位置进行控制。Linux OS具有一个IRQ关系控制接口,该接口可以让用户和程序规定哪个处理器对某个指定中断提供服务。
缓存一致性基础架构不仅在SMP用的处理器之间,而且在处理器和I/O DMA通道之间都非常管用。使用软件时要求CPU在每个I/O DMA操作之前或之后对DMA缓存进行处理。这对I/O密集的应用性能有很大的影响。使用I/O一致性硬件连接I/O DMA和存储器可以对DMA流进行排序,并能与相关的加载/保存流程集成在一起,从而有效消除软件开销。
缓存一致性管理单元应该对处理器、I/O和存储器之间的存储流进行排序。这样做增加了处理器的存储器访问时间周期,可能导致管线暂停引起的处理器周期损失。然而,每个内核使用的硬件多线程等技术允许单个内核通过执行并行的指令流来增加管线的效率。
每个内核中的线程看起来就像是运行OS软件的全能CPU,包括具有独立的中断输入。线程共享相同的缓存和功能单元,并交叉执行管线命令。如果一个线程暂停,另外一个可以执行,这样可以避免因为相关的存储器子系统延迟而导致的处理周期丢失。管理多个内核的相同SMP OS可以管理它们的相应硬件线程。为利用SMP而编写的软件自然能利用多线程处理技术,反之亦然。
两个线程竞争一个管线取得的性能将比在独立内核上执行两个线程要低。应该对SMP Linux内核进行负载均衡优化。为了优化功耗,调度器每次可以将任务加载到一个内核的虚拟处理器上,让其他处理器处于低功耗状态。为了优化性能,可以将工作任务分配到若干个内核上,然后加载每个内核的多个线程,这样所有的内核都有一个活动的任务。可以利用片上多处理技术提高SoC性能。SMP平台和软件提供了一种灵活的高性能计算平台,相对于单处理器可以大大地提高速度,而且很少甚至无需应用代码的修改。